

The vision of the smart factory looms ever larger for manufacturing leaders who see predictive maintenance as the linchpin for maximizing uptime and competitive advantage. Yet, for most CTOs, the stark divide remains between isolated sensor pilots and scaling predictive maintenance AI cost-effectively across the enterprise. With edge AI in manufacturing bridging the latency and bandwidth gaps once and for all, there’s now a viable path from scattered experiments to robust, plant-wide deployments. But how do you architect predictive maintenance AI infrastructure that’s not just technically sound, but built for performance, flexibility, and ROI?
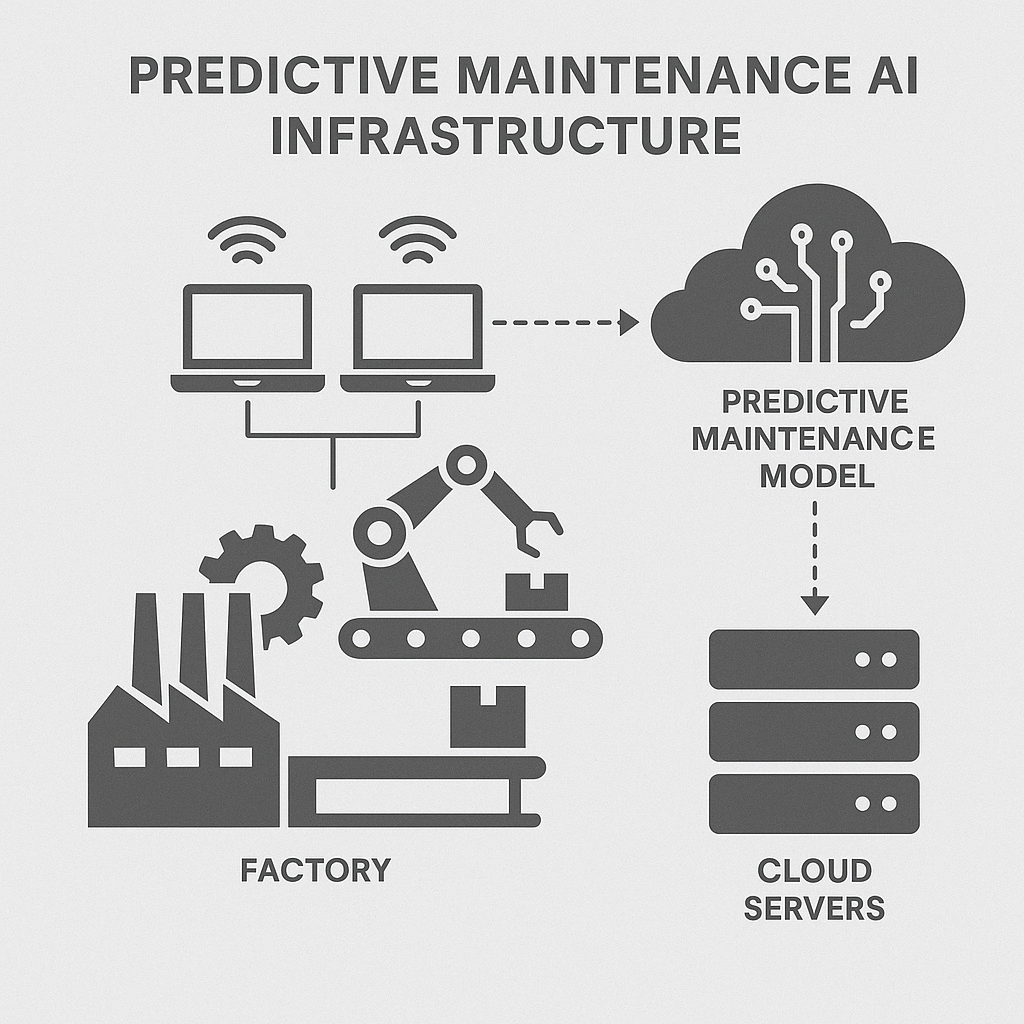
The Business Case for Plant-Wide Predictive Maintenance
Unplanned downtime remains one of the most persistent and costly problems facing the manufacturing sector. According to recent industry benchmarks, the average manufacturer loses at least $260,000 per hour of unplanned downtime. Beyond lost output, there’s the risk of damaged reputation with customers awaiting deliveries, cascading supply chain issues, and the pressure on maintenance teams to respond reactively instead of proactively.
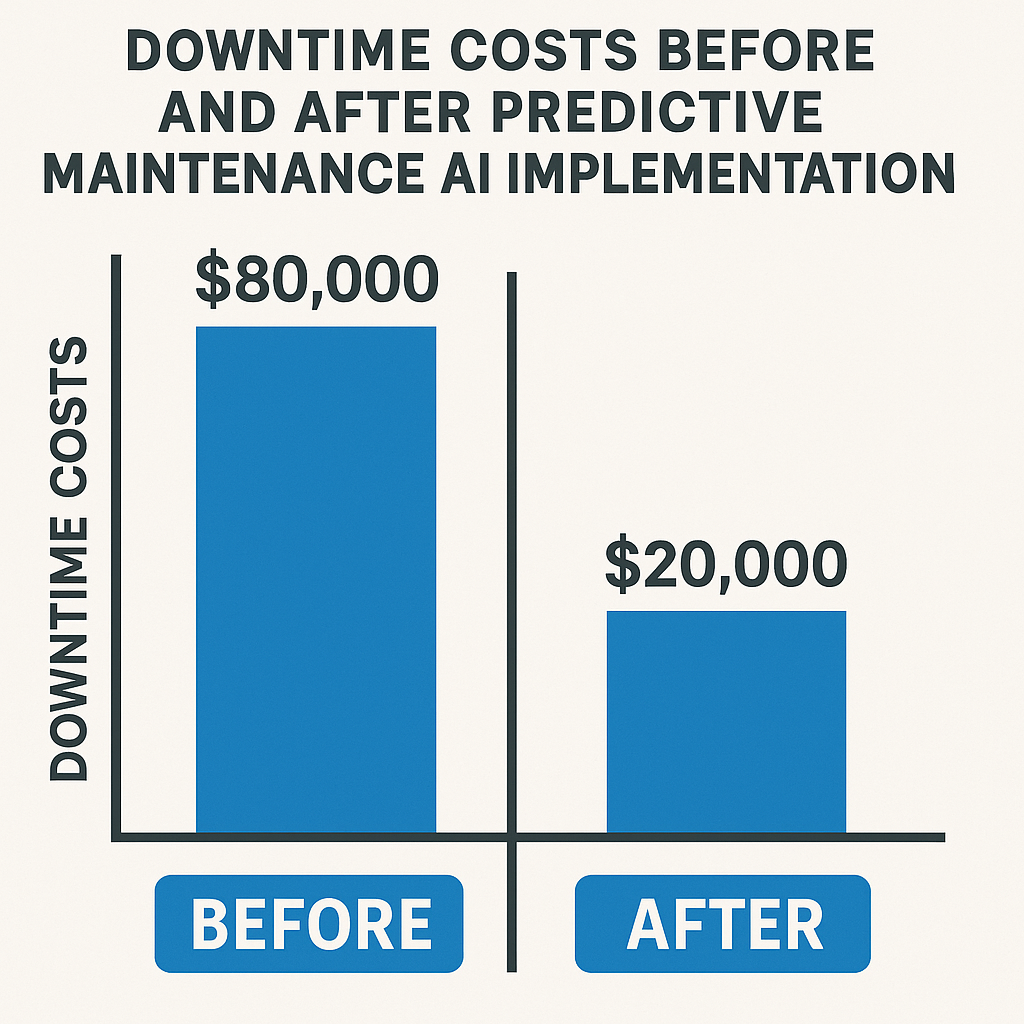
With predictive maintenance AI, the ROI equation fundamentally changes. Cost avoidance through early anomaly detection and scheduled interventions typically outpaces the capital expenditure required for sensors, edge nodes, and cloud infrastructure within the first year of broader adoption. Quick wins surface in high-throughput assets: minimising emergency repairs, reducing overtime labor, and extending equipment life cycles.
Another crucial benefit is cross-plant knowledge sharing. As you scale predictive models and amass more actionable data, insights gleaned in one facility can accelerate optimizations in others. For CTOs scaling AI operations, this is where investments begin to compound—plant-wide data agility and AI-driven best practices translating directly into both operational and financial gains.
Designing the Edge Layer
At the core of edge AI in manufacturing is the physical hardware and software stack tasked with real-time data processing at the machine level. Ruggedized edge GPUs, fanless and vibration-resistant, now pack the computational power needed for on-the-fly inferencing of complex, deep learning models. This is no small feat; latency often must remain below 50 milliseconds to enable timely maintenance actions and prevent costly faults.
Yet, raw compute is just the starting point. The most effective predictive maintenance AI infrastructure leverages over-the-air (OTA) model updates to adapt swiftly as new failure modes emerge or operating conditions shift. Meanwhile, security hardening at the edge—root-of-trust chips, encrypted storage, and remote attestation—prevents tampering or data exfiltration, a must as cyber risks grow in connected production environments.
Edge nodes also operate as the first filter, running lightweight pre-processing that slashes data volumes streaming upstream. Well-designed edge layers lay the foundation for a scalable, low-latency, and secure predictive maintenance solution—one that grows with each new line or plant coming online.
Data Pipeline to the Cloud
Scaling predictive maintenance requires an end-to-end pipeline that’s streamlined, reliable, and ready to support both immediate analytics and long-term data science needs. Protocols like MQTT and Kafka have emerged as go-to gateways for ingesting high-frequency sensor time series from the factory floor into the cloud.
Once data arrives, decisions must be made about its storage and usability. Delta Lake offers robust ACID transactions and schema enforcement ideal for enterprises dealing with diverse data sources and complex data engineering. Alternatively, purpose-built time-series databases optimize for rapid querying of sensor histories and support granular retention policies.
Compression, deduplication, and dynamic retention are not just cost optimization maneuvers—they are vital enablers for ensuring the right data is always available for machine learning model improvement, regulatory compliance, or root cause analysis. A thoughtful approach to data pipelines not only enables more accurate predictive maintenance; it drives operational agility and resilience as demands evolve.
Scaling MLOps Across Multiple Plants
The leap from a single proof-of-concept line to a globally scaled deployment hinges on a robust MLOps strategy. This often begins with instituting a central model registry, creating a source of truth for models as they are versioned, validated, and staged for deployment. Such registries make it possible to coordinate updates, rollbacks, and performance monitoring across dozens of facilities.
Federated learning takes on growing prominence for manufacturers valuing data privacy—training models locally at each plant based on their specific data, then aggregating only the insights centrally. This approach keeps sensitive operational data on-site, while benefiting from shared model improvements tailored to each facility’s unique profile.
Blue/green deployment methodologies, long used for software updates, are now defining best practice for rolling out new AI models without operational disruptions. By running new versions in parallel with existing ones, validating performance, and making phased transitions, CTOs can derisk plant-wide AI upgrades and build a feedback-driven loop for continual improvement.
Building Cross-Functional Teams

No predictive maintenance solution—regardless of engineering excellence—can thrive without cross-functional collaboration. The most successful organizations build an AI “SWAT team” by combining operational technology (OT) experts, IT systems architects, and data science talent into cohesive units with shared ownership of KPIs.
Upskilling legacy maintenance engineers is equally critical. As AI-driven tools enter daily routines, hands-on training and digital companion guides help shift mindsets from reactive firefighting to data-driven troubleshooting. These change management strategies—running brown bag sessions, celebrating quick wins, and clearly communicating expected outcomes—are what embed AI into the culture, bridging the divide between technical aspirations and real-world adoption.
As predictive maintenance AI infrastructure matures across smart factories, CTOs who blend state-of-the-art edge-to-cloud architectures with empowered, agile teams will not only minimize downtime, but unlock entirely new levels of plant efficiency and adaptability. The time to scale is now—before competitors’ machines (and models) leave you playing catch-up.
Sign Up For Updates.