The journey from exploratory AI pilot to an enterprise-grade, scalable AI infrastructure in mid-market banking is equal parts necessity and opportunity. Many financial services CIOs have weathered the proof of concept phase, de-risked innovation, and surfaced real business value. Now comes the harder challenge: translating the promise of artificial intelligence into a resilient, secure platform that supports ongoing transformation. This means scaling from tactical wins to a strategic foundation—without compromising compliance or organizational cohesion.

Why Scale Now? The Competitive Imperative
Margin pressures continue to mount in banking, nudged by low interest rates, regulatory reforms, and the swift entry of agile fintech competitors. At the same time, customers have come to expect frictionless, hyper-personalized digital experiences, often powered by smart automation or advanced analytics. According to market data from the Economist Intelligence Unit, more than 75% of banks worldwide are investing in AI to improve customer experience and fend off competition. Yet, many mid-market banks risk getting stuck in what experts call “pilot purgatory”: clusters of isolated AI efforts that never move beyond controlled environments or limited datasets.
The risk here is twofold. First, the incremental returns from isolated pilots rarely justify ongoing investment, especially once budgets tighten. Second, without a unified, scalable AI infrastructure, banks face ever-growing technical debt and operational blind spots—each new AI experiment increases complexity and risk. By accelerating toward an enterprise AI platform, banking CIOs can unlock compounding strategic benefits. These include reuse of data connectors and pipelines, standardized security controls, model governance, and the potential for AI-powered offerings to reach production quickly and safely. The question is less about if you should scale AI, but how swiftly and securely you can deliver on that imperative.
Architecture Principles for Regulated Environments
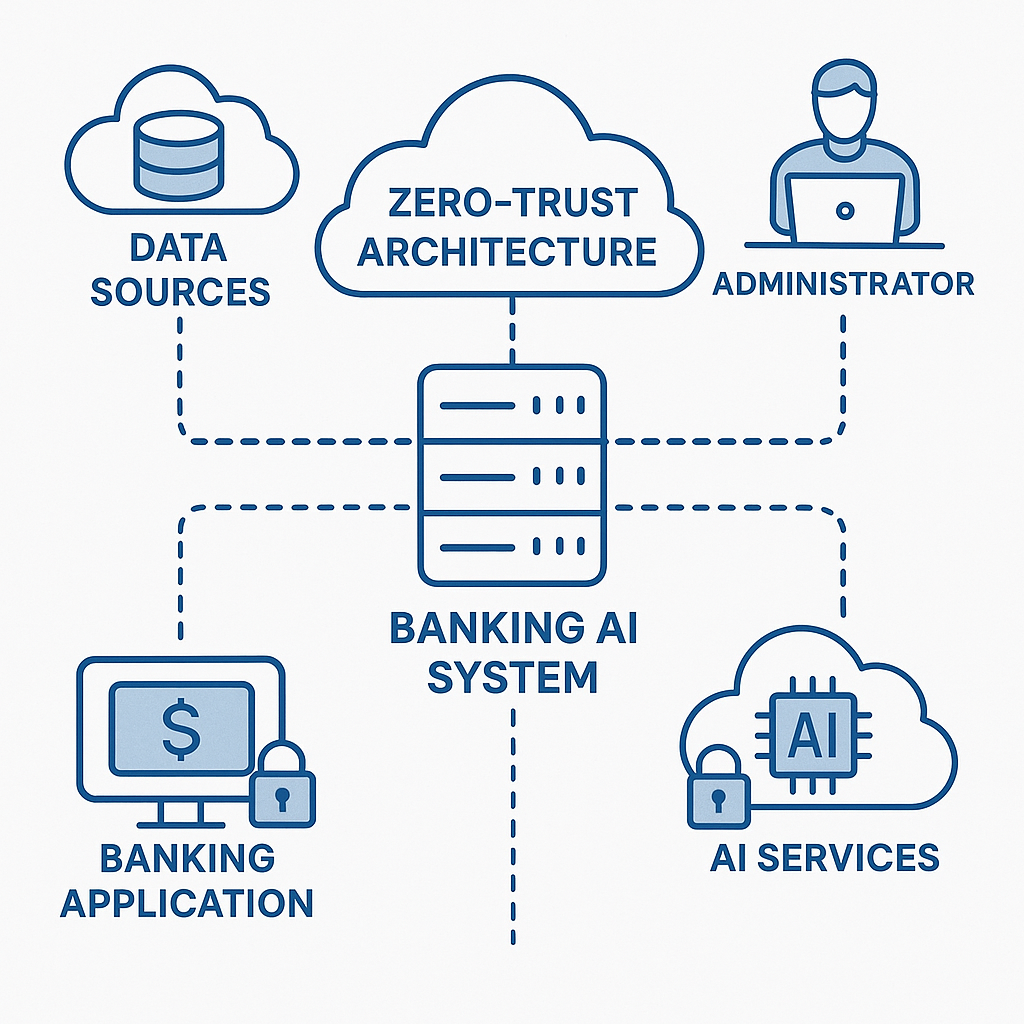
Building scalable AI infrastructure in financial services begins with understanding regulatory context. Mid-market banks must comply with frameworks such as FFIEC guidelines in the US, Basel risk requirements globally, and, for many, the GDPR’s exacting data protection rules. Each framework has profound implications for technical design choices.
First, security starts with a zero-trust network design. Instead of relying on network perimeters, every request—internal or external—is authenticated and continuously verified. Zero-trust models enforce least privilege, micro-segmentation, and rapid detection of anomalous behaviors, vital for environments handling sensitive PII and transactional data.
Second, model lineage and audit trails are not nice-to-haves. Regulators require banks to document how AI models are built, trained, and evolve over their operational lifespan. This means implementing strong version control for both data and models, rigorous audit logging, and workflows for approval and decommissioning.
Lastly, encryption is foundational. Data must be encrypted at rest and in transit, with robust Key Management Services (KMS) ensuring that cryptographic keys are rotated, stored, and accessed according to regulatory best practices. As you design your scalable AI infrastructure, these compliance requirements must be automated and deeply embedded from the ground up.
Building the Hybrid Cloud Fabric
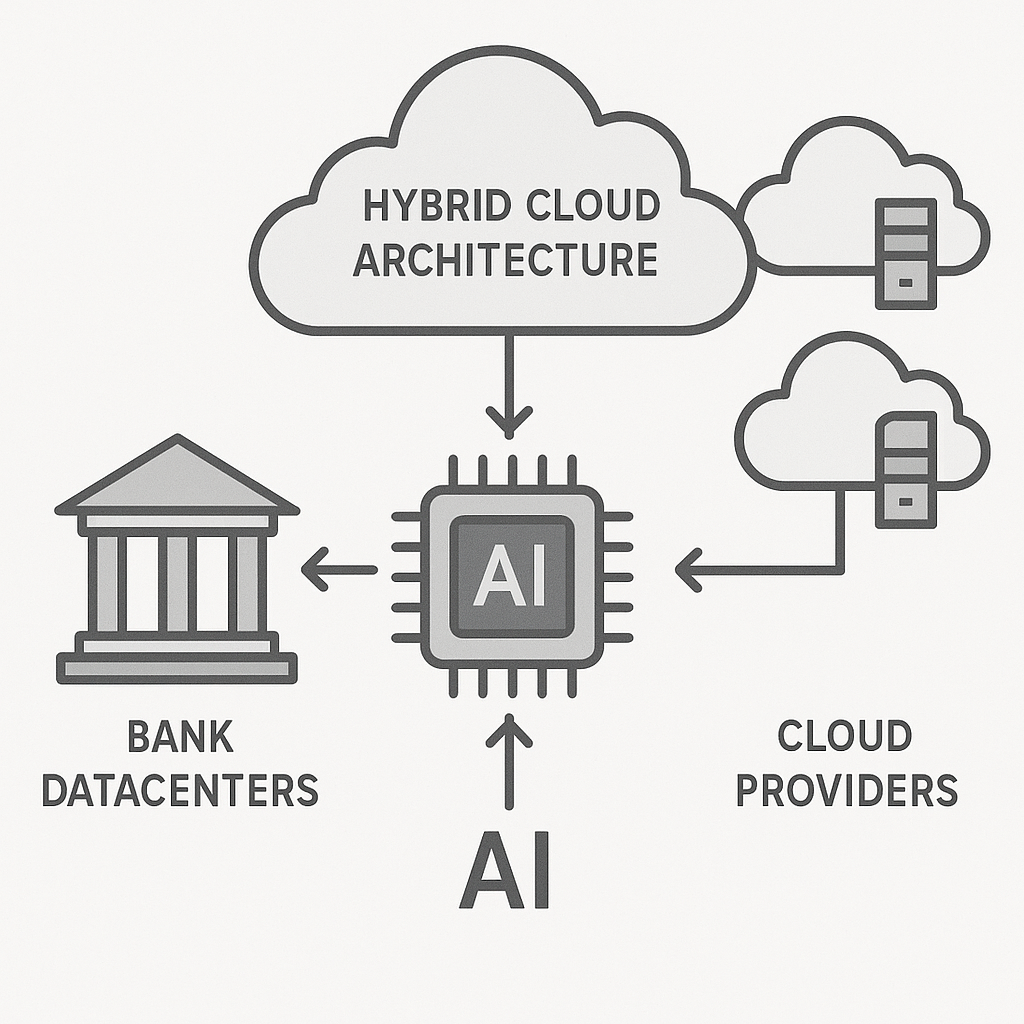
Mid-market banks rarely have the luxury of choosing between on-premises or cloud; instead, they need to integrate both. Legacy core banking systems retain critical data and enforce trailblazing security, while cloud platforms offer the elasticity and managed services needed for modern AI workloads. The result is a hybrid fabric, where data flows securely across boundaries without sacrificing performance or compliance.
Data gravity plays a pivotal role. Core transactional data is often too sensitive—and too regulated—to leave the datacenter. Yet, advanced AI models, particularly those requiring GPU acceleration, are most efficiently trained on the cloud. The key is constructing secure, monitored data pipelines. Solutions like Kafka or Fivetran enable real-time or batch integration across heterogeneous environments, while platforms such as Databricks support unified analytics and federated learning scenarios.
Container orchestration, typically via Kubernetes, enables rapid deployment and scaling of AI workloads regardless of substrate location. Banks can use GPU scheduling to optimize deep learning job execution, letting high-memory or compute-intensive models burst into the cloud while maintaining governance over traffic and costs. This careful blending of on-prem and cloud resources is central to making AI scalable, cost-effective, and compliant in a mid-market context.
MLOps at Scale
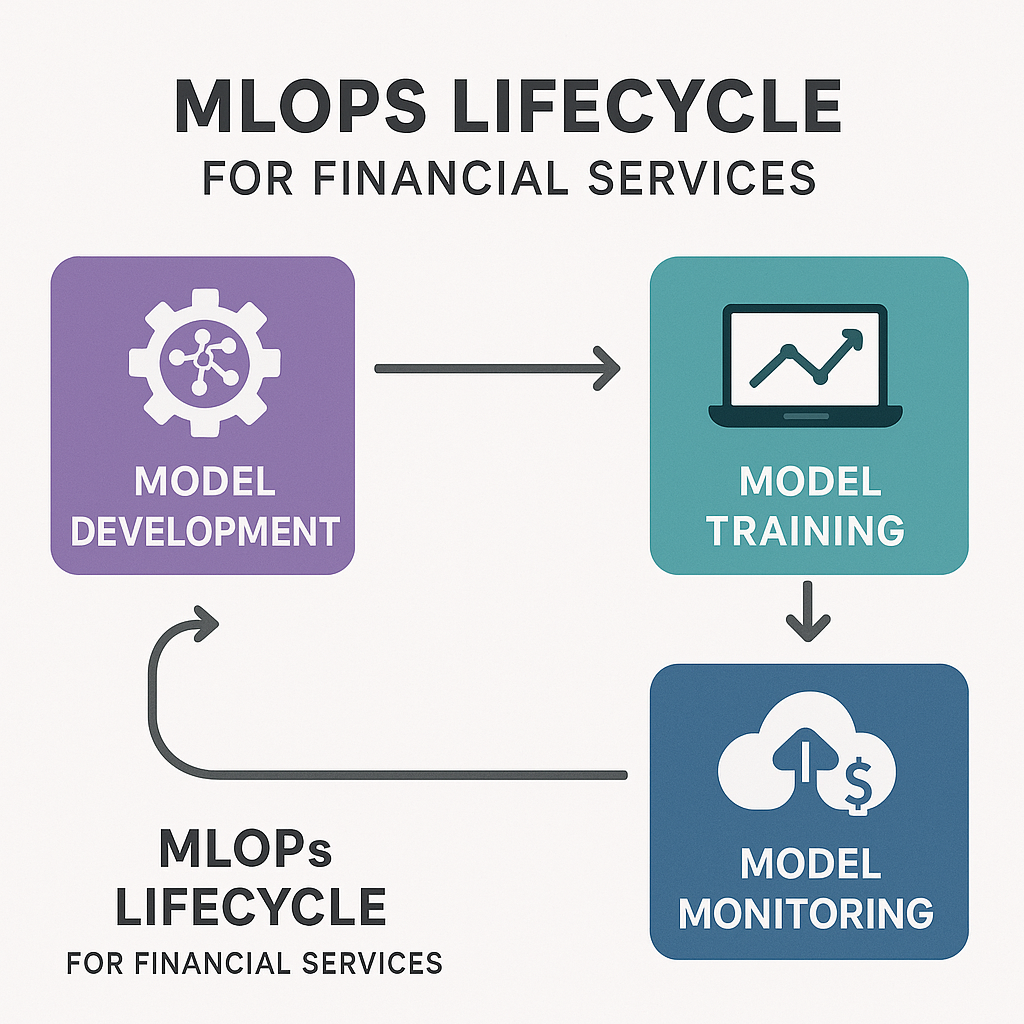
Making the leap from pilot notebooks to robust, scalable AI infrastructure means codifying the end-to-end lifecycle of machine learning development, deployment, and management—MLops. Continuous Integration/Continuous Deployment (CI/CD) practices are no longer just for app development; they are essential for reproducible, auditable model delivery. Automated workflows can test, validate, and package models before deployment to production, reducing errors and standardizing releases.
Drift monitoring is especially vital in regulated industries, where models must remain accurate, fair, and explainable over time. Automated pipelines can flag when a deployed model’s behavior diverges from expectations—due to changing customer patterns, data drift, or external shocks—triggering retraining, rollback, or human review. Governance gates embedded in CI/CD pipelines ensure that only models passing compliance, regression, and fairness tests reach end users. Rollback strategies—whether via blue/green deployments or canary releases—minimize risk, enforcing safe experimentation and rapid course correction if issues arise in production environments.
Talent & Operating Model
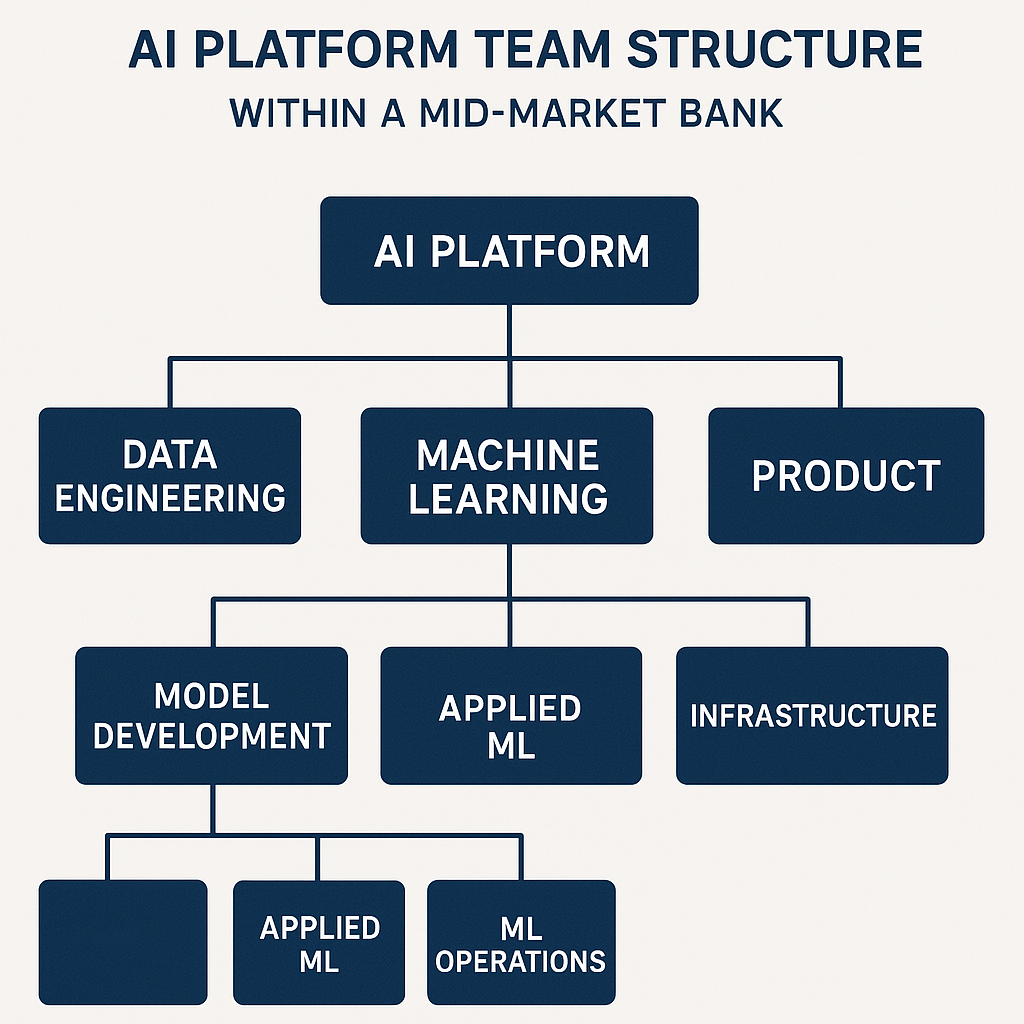
The final step in evolving scalable AI in banking comes not from technology, but from people and organization. Platform thinking requires a new operating model. Centralized AI Platform teams can build and maintain shared services—enabling infrastructure, libraries, secured environments—while federated squads of data scientists and domain experts drive business-specific AI solutions. This model avoids both the sprawl of independent silos and the bottlenecks of over-centralization.
Mid-market banks often have a deep bench of ETL and data engineering talent. Upskilling this group to modern MLOps, cloud-native design, and security practices is both efficient and empowering. Focused training can bridge gaps in tooling, cloud operations, and advanced analytics, turning legacy teams into digital accelerators.
Measurement also transforms. Instead of optimizing AI projects purely for technical metrics like model accuracy, CIOs should align key performance indicators to business value—think time-to-market for AI features, customer acquisition or retention uplift, and regulatory incident reduction. This shift ensures that the scalable AI infrastructure becomes a core growth lever, rather than another technology cost center.
For CIOs in mid-market banking, scaling AI from pilot projects to industrialized, secure platforms is a journey with significant rewards. By adhering to regulatory-minded architecture, leveraging hybrid clouds, embedding MLOps, and rethinking talent and operating models, banks can build AI infrastructures that are not only scalable, but also differentiated, resilient, and future-ready.